
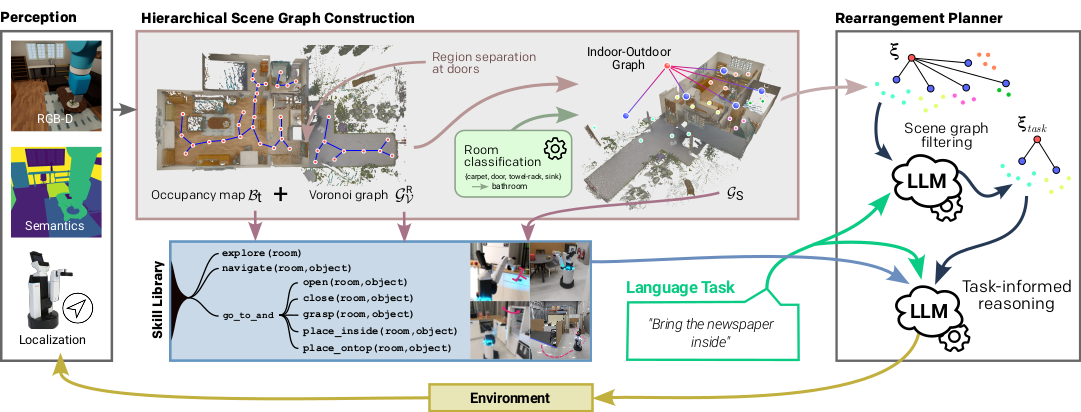
MORE: Starting in an unexplored environment, we continuously construct a hierarchical scene graph of the environment based on RGB-D data and semantic segmentation. We first build a dense occupancy map and then extract a navigational Voronoi graph. This graph is separated at
room borders based on door locations, then clustered and segmented into rooms and outdoor regions. The resulting scene graph is converted to natural
language descriptions. To generate a bounded planning problem, we first filter the observed objects by task relevance and then use an LLM as a task
planner in the resulting subgraph. The LLM orchestrates navigation, manipulation, and exploration subpolicies, which in turn result in an updated scene
representation.







